
概述
主要参考了 FNo0的baseline与wepe的特征工程。
为了方便特征提取和优化可读性,使用了面向对象编程,封装了特征提取器(FeatureExtractor)这一特征提取器类,在类中进行日期、历史、标签、线上特征的提取。
- 截止2025/04/09,本地训练auc:0.90674,线上测评0.7817
- 2025/04/09,修正用户最近一次领券据考察日的时间间隔和最远一次领券据考察日的时间间隔主键错误的bug,提高至0.7844
提高约等于0 - 2025/04/10 通过调整参数,最高达到了0.7977
- 2025/05/04 调整参数(主要是学习率),xgb模型本地训练auc:0.93937,线上测评0.8018
舒服了
xgb参数,使用了optuna超参,但最终还是主要依靠手调,xgb感觉主要是在某个区间内找出最优参数,而这个区间还是需要靠人手动进行设置,特别是在搜索轮数不高的情况下。
1 | params = {'eta': 0.020000813973175772, |
区间划分
采用了主流的时间窗口划分法,即依据领券日期进行了划分
因为是采用的领券日期进行划分,故直接筛掉了未领券人数 拼好码没有意识到的点
以下时间窗口均为左闭右开
两种划分方案:
wepe方案
- 训练集
历史区间:20160101,20160413 标签区间:20160414,20160514 - 验证集
历史区间:20160201,20160514 标签区间;20160515,20160615 - 测试集
历史区间:20160315,20160630 标签区间:20160701,20160801
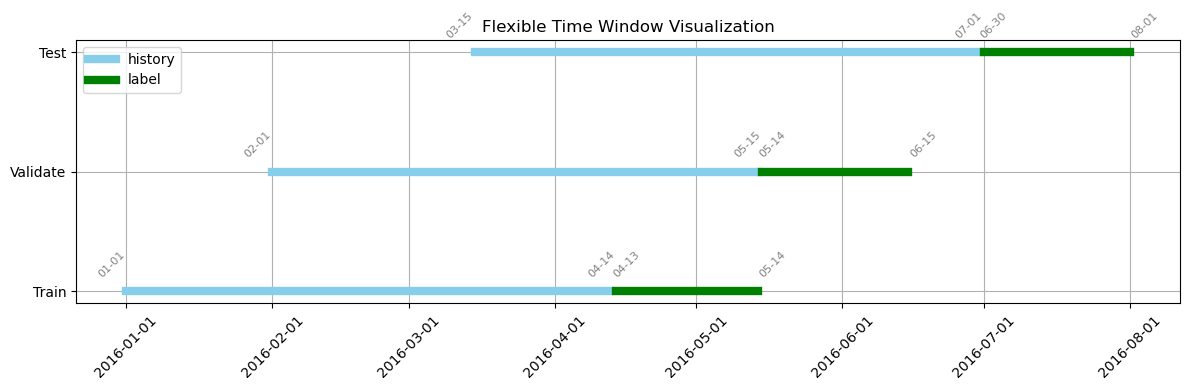
这种方案最大限度地利用了一切可以利用的数据,适合用于比赛上分,实测这种方案在相同模型和参数情况下一般会比FNo0的方案高出一些分数。最终我使用的也是这种方案。
代码:
1 | #训练集 |
FNo0方案
训练集:
- 历史窗口:60 天
- 中间窗口:15 天
- 标签窗口:31 天
验证集 & 测试集:结构类似,按顺序滑动
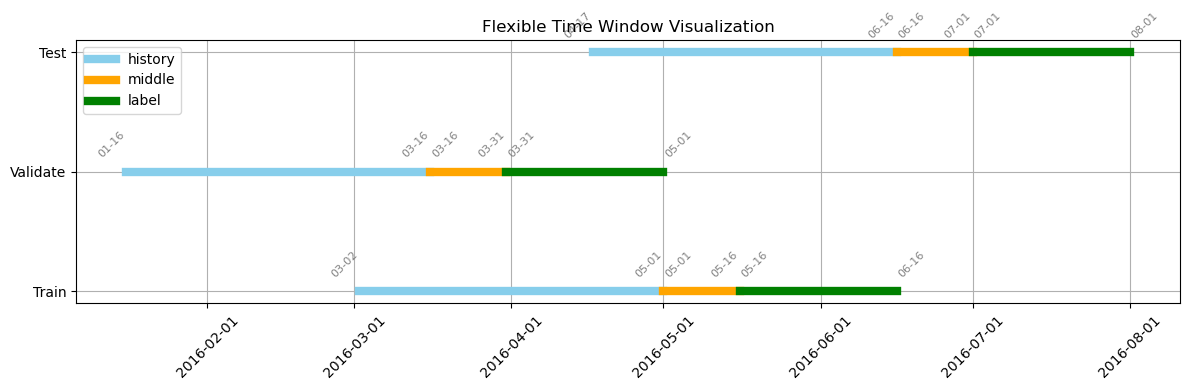
这种方案划分严格,比较完美的规避了划分带来的leakage问题,适合用于实际场景。
代码:
1 | train_history_field = off_train[ |
特征工程
目前完成的特征
标签区间特征
该部分主要利用了数据的leakage,即:若用户重复领券,特别是重复领取了相同的优惠券,那么使用上一张优惠券的概率会大大提高。基于上述原因,这个部分的特征也是可以用于大量上分的特征,实测大概在0.4~。
- 用户领券数
- 用户领取特定优惠券数
- 用户当天领券数
- 用户当天领取特定优惠券数
- 用户是否重复领券
- 用户最近\最远一次领券据考察日的时间间隔(考察日取领券日期最大值)
- 是否第一次\最后一次领券
- 用户该日之前\之后领券数(出现问题,准备重写)
- 用户领取了多少优惠券
- 距离用户上一次领取的时间间隔(出现问题,准备重写)
- 商户被领取了多少优惠券
- 商户发行了多少种优惠券
- 上旬\中旬\下旬领券数
- 用户领取特定商家优惠券数
- 商家被领取的特定优惠券数
- 用户领取满减券数
历史区间特征
用户特征
- 用户历史消费次数
- 用户历史领券数
- 用户历史核销次数
- 用户核销率
- 用户对商家券的15天内核销次数
- 上旬领券次数
- 中旬领券次数
- 下旬领券次数
- 领取并使用满减券次数
- 领取并使用非满减券次数
- 核销优惠券的平均折扣率
- 核销优惠券的最高折扣率
- 核销优化券的最低折扣率
- 核销优惠券的平均距离
- 核销优惠券的最大距离
- 核销优惠券的最小距离
- 在多少不同商家领取并消费优惠券
商户特征
- 总含优惠销售次数
- 商家优惠券被领取次数
- 商家被哪些不同客户领取
- 商家的券被核销的次数
- 商家提供的不同优惠券种数
- 发放满减券次数
- 领取非满减券次数
- 优惠券的平均折扣率
- 优惠券的最高折扣率
- 核销优化券的最低折扣率
- 核销优惠券的平均距离
- 消费的平均距离
- 核销优惠券的最大距离
- 核销优惠券的最小距离
优惠券特征
- 优惠券被领取的次数
- 优惠券15天内被核销的次数
- 优惠券15天内的被核销率
- 15天内被核销的平均时间间隔
- 满减最低消费中位数
- 满减券被领取次数
- 非满减券被领取次数
- 核销优惠券的平均折扣率
- 核销优惠券的平均距离
用户-优惠券特征
- 用户领取该种优惠券数量
- 用户核销该商户优惠券的数量
- 核销优惠券的平均折扣率
- 核销优惠券的最高折扣率
- 核销优化券的最低折扣率
- 核销优惠券的平均距离
- 核销优惠券的最大距离
- 核销优惠券的最小距离
商家-优惠券特征
- 优惠券被领取的次数
- 平均被核销多少张
- 优惠券15天内被核销的次数
- 优惠券15天内的被核销率
- 15天内被核销的平均时间间隔
- 满减最低消费中位数
- 领取满减券次数
- 领取非满减券次数
- 核销优惠券的平均折扣率
- 核销优惠券的平均距离
用户-商家特征
- 历史消费次数
- 历史领券数
- 用户核销次数
在线特征
在线区间未按时间窗口进行划分
- 用户特征
- 用户在线操作次数
- 用户在线购买数
- 用户在线点击数
- 用户在线不消费数
- 用户线上核销数
- 用户线上领取率
- 用户线上购买率
- 用户线上点击率
- 用户线上核销率
时间特征
- 领券为周几(独热编码表示)
- 是否为工作日/休息日
- 在一个月的第几天领取
组合特征
- 用户线下的优惠券核销次数占线上线下总的优惠券核销次数的比重
- 用户线下领取的记录数量占总的记录数量的比重
模型融合
rank融合
总结
- “拼好码”的前提是读懂代码,对提取的特征把握不清晰约等于没有提取,目前而言,AI其实是不聪明的。
- 不能把握这个特征的具体情况就贸然使用代码,反而会降低模型可信度。
- 调参很重要,要做好每次调参的备份,方便基于历史数据进行参数调整。
- 多做多想多总结。